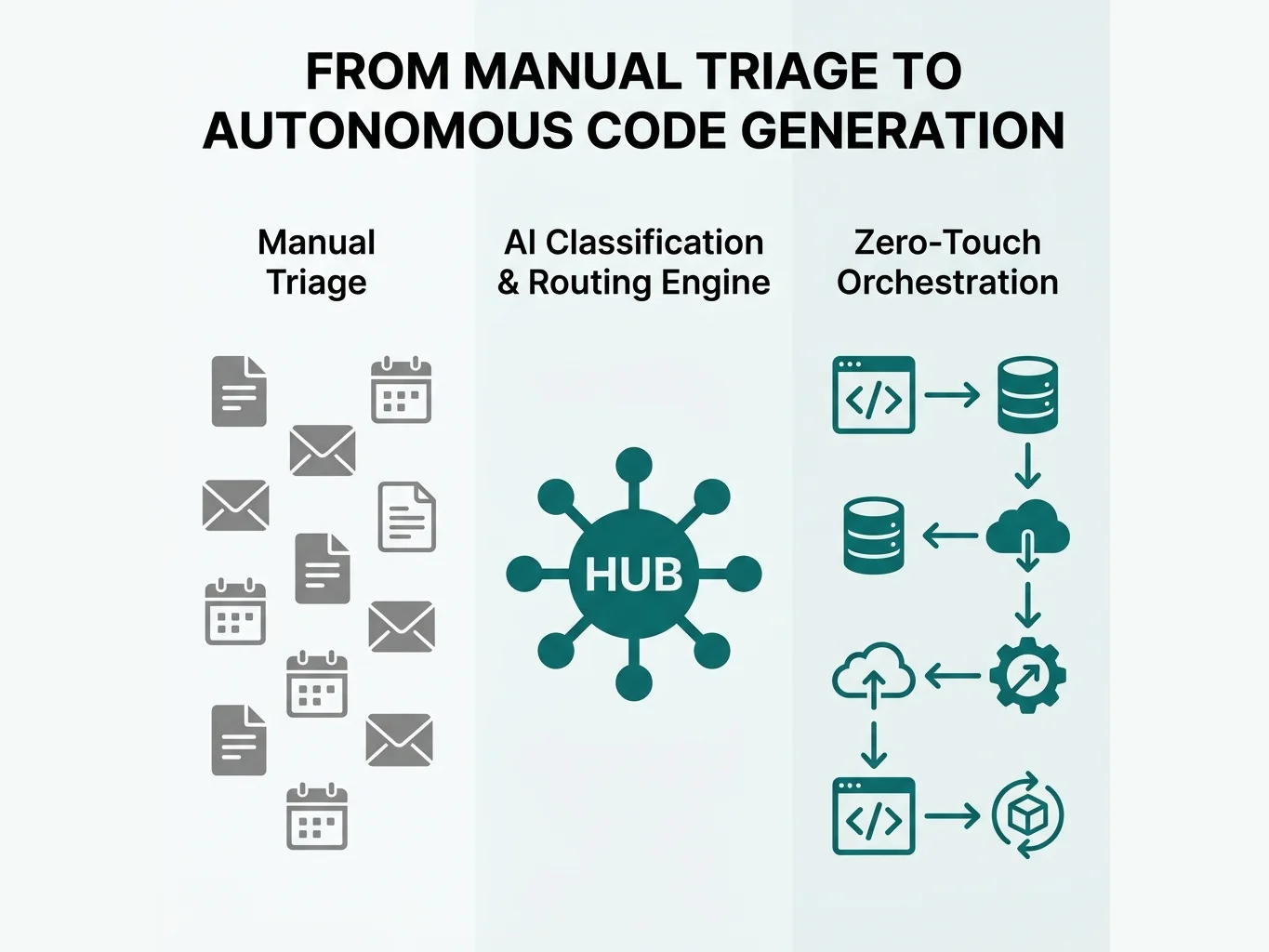
The Challenge
Designing an AI ingestion layer that mitigates enterprise hallucination fears — across heterogeneous data sources where format, structure, and routing rules differ by source and project. The system required absolute integrity: a guarantee that records could be generated dynamically without ever risking corruption of source data.
The Approach
I engineered a multi-channel orchestration pipeline built on a strictly decoupled "archive and react" pattern. Eleven ingestion channels — email APIs, calendar events, meeting transcripts, physical document scans (OCR), cloud document exports, IoT and wearable data streams, RSS intelligence feeds, financial document extraction, billing and renewal monitoring, CRM exports, and OS-level task execution engines — feed a composable, PID-locked pipeline where Gemini classifies each input by project, urgency, and domain, then routes it to the correct knowledge silo. An autonomous RSS-to-code pipeline maps industry news against a known taxonomy, discovers new entities, and writes directly to a production codebase that auto-deploys. A unified contact intelligence layer merges five data sources with fuzzy deduplication and tier-based relationship management, generating pre-meeting briefings from conversation history. The entire system operates read-only on inbound streams, with append-only structured outputs bidirectionally synced to OS-level execution engines.
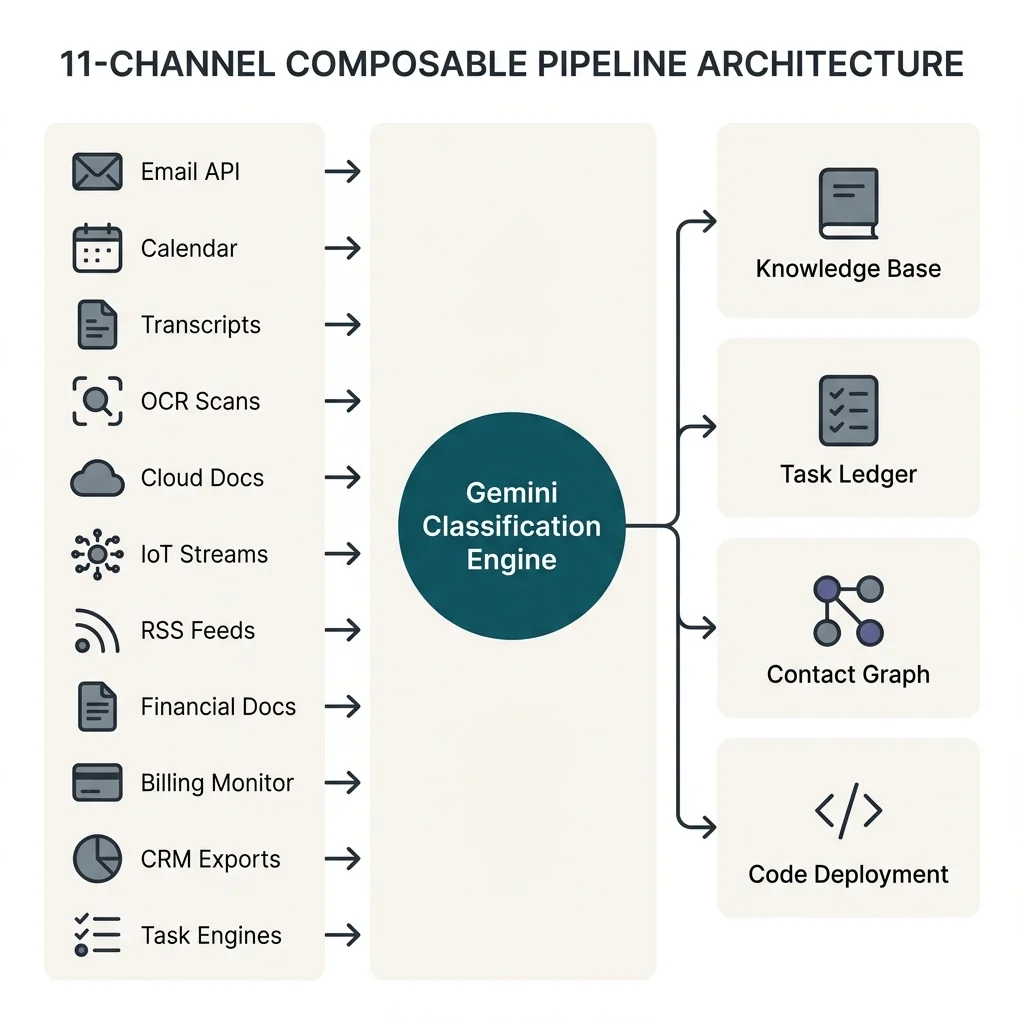
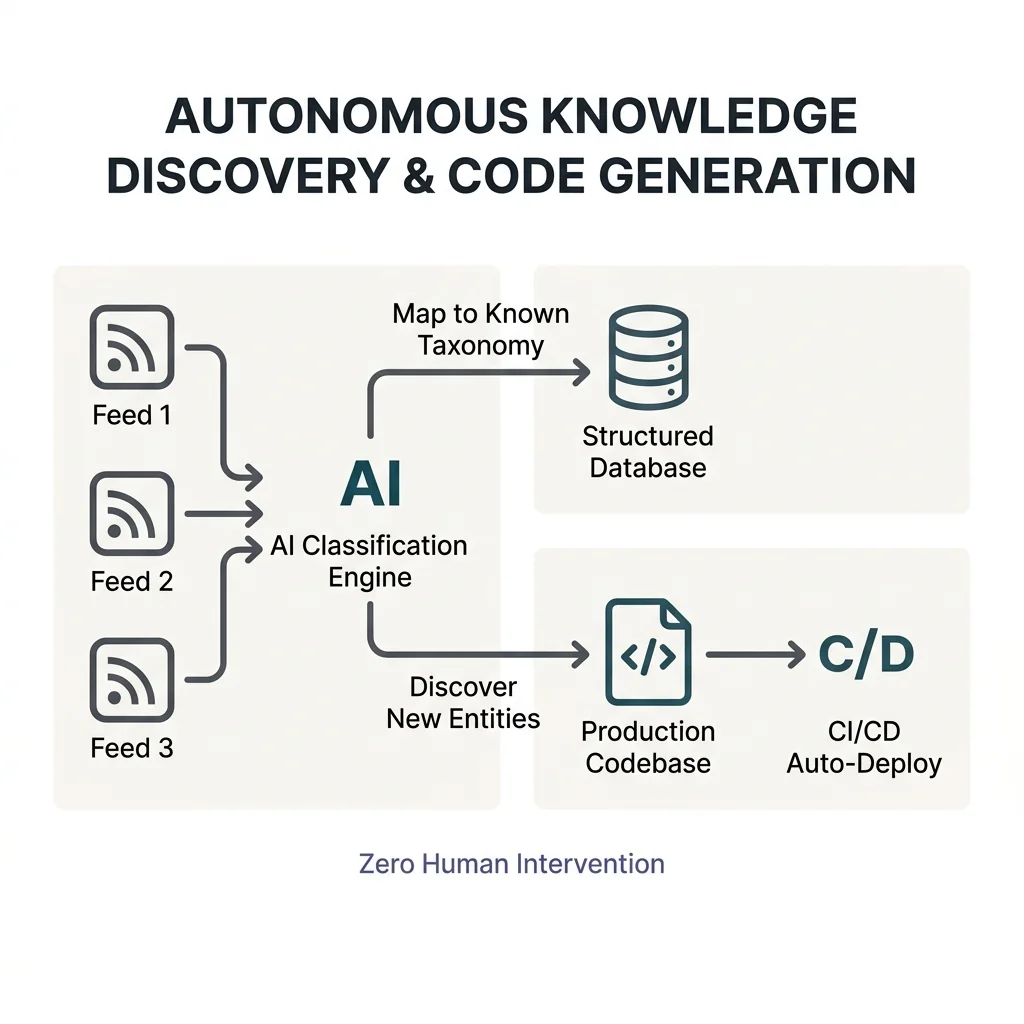
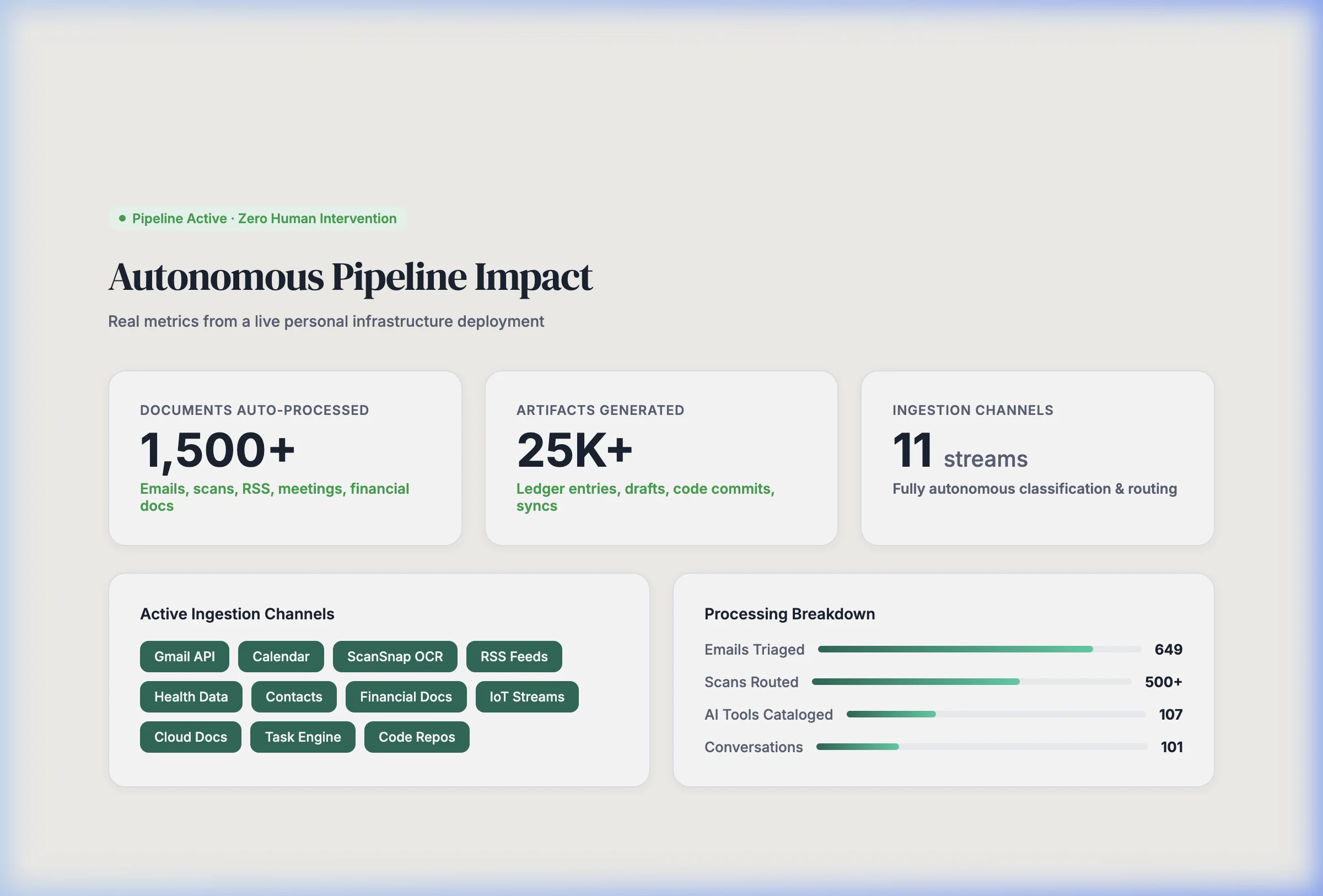
Impact
The pipeline autonomously triages and routes inputs from 11+ channels, maintains a unified contact knowledge base across 5 data sources, and generates pre-meeting intelligence briefings — eliminating 100% of manual triage overhead. Over 1,400 documents have been processed with zero data loss or corruption, including a 672-document historical batch processed in a single overnight run via Gemini 2.5 Flash.
